AI Agent For The OCTI Board Game
Introduction
Board games that are converted into digital versions is a phenomena that recently has gathered momentum. Famous games such as checkers, chess, backgammon and others are already digitized. This allows players to play their favorite games any time and anywhere, without the necessity of arranging physical meetings or owning a physical copy of the game. Moreover, players, both amateur and professionals, can now play and train against computer.
The ability of playing against the computer allows human players to play without a partner and therefore makes the game more accessible. In addition, one can choose the level of difficulty for the virtual opponent or undo some several badly chosen moves. Thus, the game becomes a controlled training ground for players to develop and advance their skills.
The OCTI board game is a relatively new one, compared to the classical games like class (500 yr.) or go (2,500 yr.), and was yet to become digitized, unlike the latter mentioned games [7, 8]. The game involves two players, playing against each other. Each player has four pieces (standing on a base locations at the beginning of the game) with octagonal shapes (thus the name of the game). The game is played on a six by seven grid. A player wins by either landing a piece on any vacant tile of the opponent's base , or by capturing all opponent's pieces. The game is played in turns. In each turn, a player can either add an arrow to one his pieces 8 edges, which in turn allows the chosen piece to move ,in later turns, in the direction where the arrow points. A piece can jump over a rival piece if the position behind the piece in the direction of movement is empty. By doing so, the jumped over piece is captured or eaten , i.e, is removed from play. A piece can jump over as many pieces as available in a single turn (similarly to checkers, only here it is allowed not to capture if one desires). A piece can also jump over pieces of its own team only in that case the jumped over pieces are not affected.
In this paper, we develop and evaluate the performance of three artificial intelligence (AI) agents, in three levels of complexity, that play OCTI. During the work, we developed and deploy an OCTI online game. This post organized as follows. First, we present the game, its rules and the web application interface used to develop a digital version of the game. Second, the three AI agents developed for the game are presented. Third, the results of evaluating the AI agents against human player and against each other are presented. Finally, we discuss the outcomes and methodologies used in this project and possible future improvements.
OCTI
OCTI is a strategy box game for two players. The OCTI game has two main styles that differ one another in the number of pieces (toys) each player has, the board's size, base locations, and action rules. In this manuscript, we develop the less popular version of four pieces, with bases located in a column and the board is 7X6 as this version does not have a digitized version online.
Game Rules
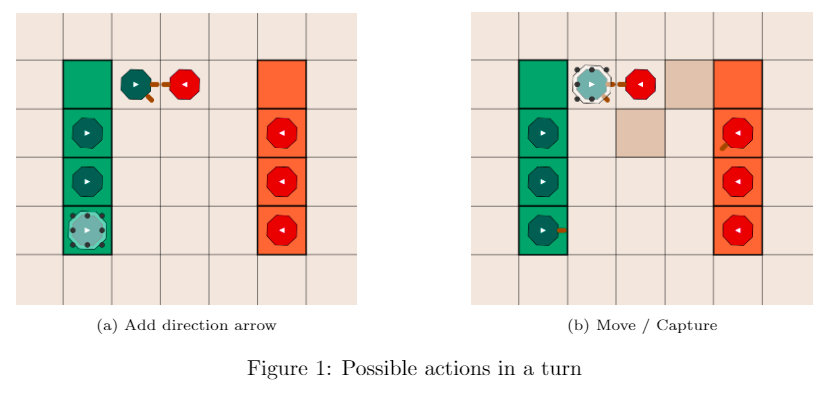
The game starts when both players have their four pieces standing on marked home base locations. The game is turn-based when the green player is the first to take a turn. In each turn, the player plays by clicking on the relevant piece. Then, he can either add a direction arrow to it, or move to a desired location, as shown in the figure below. In case a player "jumps over" an adversary piece and is able to jump over additional pieces, he can do so in the same turn. The game is won by one of two ways: when a player lands a piece on one of the opponent's base tiles, or when a player manages to capture all opponent's pieces.
Project structure
The game is developed as a single-page website, in pure JavaScript (JS) programming language with the P5 library. The game's board is rendered once on page load and then the pieces and mouse cursor are rendered in each frame. When a player wins the game, a winning message appear and after some delay the game resets.
The project structure is as follows:
- sketch.js: is the main file in the project that responsible for the player-game interactions and implements the P5.js logic to render the game visualization. On page load, it initializes the game and in each frame renders the board. In addition, it contains all the game's logic and events of the user's actions.
- toy.js: contains a player's toy class that has its current location on the board, color, id, and list of possible directions it can move to.
- game.js: contains the two players as list of eight pieces (four for each player). This class manages the interaction with the AI players by providing an interface to the game's state and interpretation to the AI player's action.
- move.js: contains a data structure class that holds the data and meta data regarding an action.
- player_move.js: contains a data structure class that holds the data and meta data regarding an AI player's action.
- global_math.js: contains common mathematical operations.
- ai_player.js: has all the AI player's classes. All these classes implements two methods: do_move(game) that receives an instance of the Game object and returns a player_move instance. Similarly, a do_continue_jump_move(toyId, possibleMoves) method which gets the current toy's id that makes the move (as an integer) and list of possible moves for this toy (as a list of player_move instances) and return a player_move instance from this list.
- ai_util.js: is a helper class, providing an easy to use interface to download and load from server files (specifically, the AI's models).
- game_history_ai.js: is a class that operates as a logger to the game which later used to train a RL agent which is based on sampling multiple games and their results.
- extended_game_history_ai.js: inherits from game_history_ai.js class, and is used for logging the data of numerous games at once.
- q_learning_policy.js: is the "brain" behind the RL-based agent of the game, where the class manage two main operations. First, the online learning by updating the model's weights due to the games it participated at. Second, providing the optimal step for each game's state (with some chance to explore new states).
- policy_offline_learner.py: is responsible to get a list of game_history objects (as Jsons) and prepare the data structure later used by the q_learning_policy class. This file is exceptionally written in Python and not in JS for reasons of convenience. It should be noted that this file is for the development stage only and is not used during games.
- aivsai.js: allows to run the game for two AI players playing against each other. This is essential for generating large quantities of gaming data. The data in turn is crucial for the training and development of the RL player.
Web application interface
The game is developed as a stand-alone pure front-end web application. The project is based on the concept of a single page, where a single HTML page is loaded whenever a user enters the website. The content is updated via the JS source code based on the user's actions.
At first, the user is able to pick one of five options: 1) play on the same computer with another user. 2) play against an easy (greedy) AI agent. 3) play against a medium (MinMax with 3 steps look ahead) AI agent. 4) play against a hard (RL) AI agent. 5) play against an AI agent that is based on a code the user enters.
If the user picks one of the first four options, the game's main window opens with the game board and description of the moves (actions) done until this point. Otherwise, the user picks the fifth option and the user's AI window is open with places where the user can enter his own code for the AI agent's action picking logic while provided with the game's object and a list of all possible moves (actions) the agent is able to do.
AI Player Methodology
In order to develop several levels of AI players that a player can pick from, we decided to develop each AI agent using different algorithmic approach rather then to add constrains (e.g, computation time, number of steps forward the agent takes into consideration, etc.) to one type of AI agents [1]. We develop two deterministic algorithms based agents (greedy, MinMax) and a classical RL based agent [2]. We picked the first two level of AI agent complexity to be deterministic thanks to their productiveness which shown to be an important feature in AI agents in games, allowing a human (and AI) player to become better by trial and error [6]. Later we used these players to obtain the needed data to train the RL agent which designed to provides richer experience to the user which better mimics a human's style thanks to the exploration-optimization feature.
This section organized as follows. We describe the development of each AI agent - greedy, MinMax, and RL. Than, we describe the evaluation method of an AI agent.
Greedy player
The greedy algorithm based player is based on finding the best state for a given game's state. The greedy algorithm gets the game's state and a list of all possible actions. The greedy algorithm evaluate each action using a heuristic metric.
The greedy algorithm divides the possible actions into two groups of actions: add direction and move. An add direction action is an action where we add a direction to a chosen piece. The move action includes a one step move of a toy in the direction of one of its available directions, jumping over a friendly (with the same color) toy, jumping over an enemy (with an other color) toy and by that removing it from the game board. Several jumps considered in a turn considered as several actions the agent needs to perform.
The greedy algorithm works as follows. In case of an add direction action, the action's score is calculated by reducing the minimal distance of the piece from the opponent's base in the next turn, would this piece will move in the new direction, while ignoring other players (that may prevent such move from happening). In the case of move action, the action's score is depended on three main factors. First, reduction of the piece's minimal distance from the opponent's base. Second, if the piece may jump over an enemy piece, there is a constant value added to this action's score. Third, if the toy may be jumped over next step by the other player, a penalty, in the form of a constant value, is reduced from the action's score. A move action that results in a piece either jumping over the last enemy piece or landing on opponent's base locations, this action gets the highest possible score possible.
MinMax player
The MinMax algorithm based player is an extension of the greedy algorithm as it uses the greedy algorithm to determinate the score of a single move. This algorithm extends the greedy algorithm by adding linear penalty to the number of friendly pieces that have been removed from the board and gives bonus for capturing enemy pieces. Another aspect that is introduced is a bonus for each added direction arrow, as one will preserve pieces with high directional mobility due to their capabilities and the amount of turns 'invested' into them.
Theoretically, since each action is deterministic the MinMax algorithm is able to determinate all possible games possible to be played and therefore determinate the winning strategy for any action the opposite player would take. Nevertheless, due to the enormous number of possible games it is practically unrealistic to compute all these possible games. In addition, as the algorithm computes the next step in real time, it must be fast enough such that it does not makes the human player to wait to much and harm its experience. Therefore, we compute the average time it takes to the MinMax algorithm to make a decision, given n = 1000 random states of the game on average as a function of number of steps ahead the algorithm covers (i.e., the depth of calculation). The results are summered in the table below.
| Look ahead steps [1] | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Average time in seconds (n=100) [t] | 0.03 | 0.48 | 3.21 | 87.55 | 1298.07 | too long |
RL player
The RL based player is based on sample based RL, where the value of each state is estimated from experience [10] . The states are treated as nodes in a graph, and the actions are the edges of connecting the states respectively. The value-based approach doesn't store any explicit policy, only a value function. The policy is derived directly from the value function, by picking the action the will lead to best value.
The main reason we choose to implement a sample based approach and not a more classical model-free algorithm like Q-learning is the issue of space complexity. The requirement of sweeping the state space S for policy optimization, which in the Q space is even larger with |Q| = |S x A| leads to an exponential algorithmic complexity [4]. To illustrate this the following equation gives an upper bound for Q-space magnitude |Q|.

where k indexes the number of developed arrow directions and i indexes the occupant tiles on the board. To illustrate this even better, the order of magnitude of the result of the outer summation only is 10^20.
Another possible approach in RL is deep reinforcement learning [5]. This approach does not fit our needs as well because of the structure of project that is based on single web page that performs all the calculations online without the aid of external cloud services etc. First and foremost, web-based calculations receive small amounts of memory from the browser, that the optimizes the overall performance. Thus, the depth of the potential model is highly restricted, while typical deep RL models somewhere from hundreds of MB up to few GB of memory. The second reason was less practical for us, is the much larger data sets needed in deep approaches. Since our game is quite rare all the data for the training needs to be generated by us.
The value of each state is estimated by averaging the returns observed after visits to that state. Theoretically, by sampling infinity games, the sampled value will converge to the expected value according to the central limit theorem [3]. Naturally in our case, an episodic sampling means sampling full games. The return for all states observed in an episode is 1 for a win and -1 for a loss.
The RL player is provided the game's state and all possible action for this state. Similarly to Q-learning methods we incorporate epsilon-greedy policy for exploration and exploitation. With a probability of epsilon the algorithm chooses an explorative action by returning an action that leads to a yet visited state, or in case there are none unexplored neighboring states, it chooses the least visited one. With (1-epsilon) probability the policy chooses an action that is optimal (according to its current best estimate of the optimal policy), and so it exploits the environment. If there are multiple neighboring states sharing the highest value, the algorithm picks one randomly.
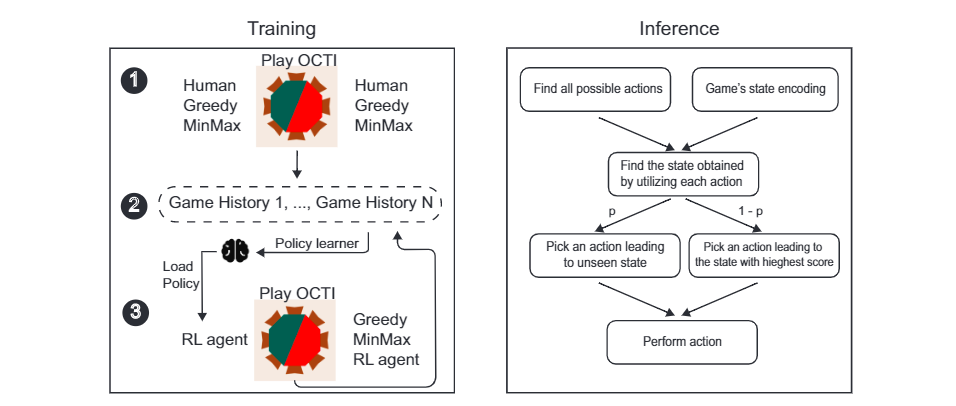
A schematic view of the RL agent related logic, divided into training and inference stages, is shown in the figure below.
Game’s state encoding
with the directions added to them during the game. Since a piece may be captures during the game, its necessitates a special way to encode it. In addition, each piece has a color (flag) which indicates which of the players own it. Therefore, one can describe the state using an 80-dimensional array; Each 11 elements describe the following attributes: the first two values hold the x and y location coordinates. The additional eight values binary indicate if a direction is added to the piece. A special value (for example -1) indicates if the piece has been captured.
It is possible to represent the game's state even more compactly using 16-dimensional array where each two adjacent pairs of values indicate a piece coordinates on the board (using a number between 0 and 41) and the directions added (using a number between 0 and 127 representing the eight binary number which indicates if a direction has been added or not).
Action's encoding
The possible actions in the game are divided into two groups: adding a direction to a piece or moving it. Either way, an action is done on a specific piece according to its identification number. The first group requires one value describing the index of the direction. For the second group, we encode the new location as an index on the board. Therefore, it is possible to describe any action using three dimensional array where the first value is the piece's Id, the second value indicates the type of action and the third value indicates the location's index on the board or the direction index - according to the value of the second value.
Training
The training process of the model can be divided into two main stages: an offline learning and an online learning. In the offline learning stage, human and AI players played against each other, logging the states observed during the game and the winner's Id. Later, the data gathered was used to evaluate the state's initial value by the number of times a player visited this state and won/lost, divided by the number of times the state was observed. This process results an initial policy for the RL agent. Afterwards, the RL agent is played against the other AI agents including itself. After each game the states' values were updated.
After the offline learning is completed, the the model for the RL agent has been deployed online for human players to play with. Here, each player is allocated an Id number (using a web cookie) which stores the state and winner's (player or AI) in all the games the player played with the RL agent. When starting a new game with the RL agent, the state's scores of the model is updated online according to the game's played with this specific user.
Evaluation
In order to evaluate each AI agent from game's prospective, we conducted a tournament between human and AI players. The tournament held as follows. We asked five different human players in different levels of mastery (first time player, player that played a few dozen games, the two developers of this AI, and a master player according to the Israeli OCTI society) to play with each one of the AI agents for 10 times. The order of the games with the AI agents were decided randomly for each human player by shuffling a list AI agents names. From each game, we stored if the AI won or not and how many actions it took for the AI to win (when it does). In addition, we compared the performance of the AI agents. Each AI agent is played 1000 times against each of the other players. Similarly, we stored if the AI won or not. In order to eliminate the inherent advantage of the opening player, for each player, either human or AI, the number of times they played as the opening player was equal to the number of times they played as the second to play player.
Results
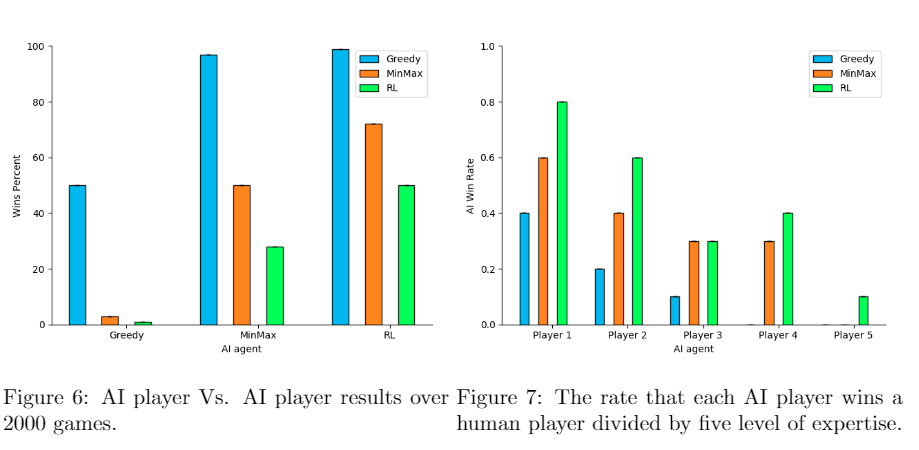
To illustrate the advantage of the RL based AI player we performed a series of tests as described in the previous section. Firstly, we ran the different AI agents to play against each other for a total sum of 2000 games, when the identity of the opening player is switched so each type of agent half of the times is playing first and half of times is playing second. The runs were automatically conducted using aivsai.js module. All the runs were made after the training period, in which the RL player reached some convergence. The results are graphed in the figures below. As a sanity check, we examined the the graph bars related to the AI agents playing against themselves (e.g. greedy vs. greedy) and verified that indeed the win percentage is exactly 50% . The greedy player bars clearly show the dominance of the MINMAX and RL agents over it, with nearly zero winning percentages for the greedy player when playing against them. Looking at the bars of the MINMAX and RL agents we see a substantial improvement of the RL agent over the MINMAX, with win percentage 76%.
The next test was conducted using five volunteers with different levels of expertise in the game, starting with players first time playing and ending with a master player. The players played 10 games against each of the AI agents in a random order. As expected, a clear monotonous trend is reflected from the graph for all AI agents, where the higher the skill of the player the better the performance against the AI. More importantly, is that the win averages of the RL agent are higher than the other AI agents for all most all the players that participated, with a single exception of player 3, for which RL performance equaled to the MINMAX agent. What even more impressive is that the RL agent was the only AI agent that manged to beat the master player at least once, as shown by the bar on the right.
Discussion
In our project we developed an online digitized version of the OCTI board game. The main challenges we faced at first when tackling the RL player development were all connected to the later realization of the uniqueness and complexity that characterise the general family of board games - "Multi agent adversarial problem".
Although, multi-agent reinforcement learning (MARL) has been studied for some time already, only in recent years this domain re-emerged due to advances in single-agent RL techniques [11]. One of the main reasons for this, is the issue of scalability. It should be noted that OCTI can be analyzed as a two-player zero-sum setting, however, this can be misleading, since in our case each player has several pieces he can choose from and different type of actions for each piece. We speculate that these settings of the game are the main reason for the higher complexity of the problem compared to more classical RL solved problem like a race car on a track.
Looking at the results we conclude that our RL agent achieved some convergence, as otherwise it would not have outperformed the other AI agents and especially the MINMAX agent, which despite its deterministic nature play plays quite solidly against human players. We speculate that would our MINMAX agent were more effective the rate of convergence of the RL would have been faster since the former was the main source of initial training data for the RL. However, it was not practical to deepen the MINMAX further than 3 steps look-ahead since for already for 4 steps it would have taken an average of 87.55 seconds for each step of the AI, as seen in the table above. Those times are closed to infinity in web based projects that rely on human interaction.
Our suggested future work, based on the platform we developed and built, is to employ the strengths of genetic Neuroevolution techniques for the development of stronger AI agent [9].
References
- Guillaume Chaslot et al. “Monte-Carlo Tree Search: A New Framework for Game AI.” in: 2008.
- Vladimir Fedorovich Demyanovand, Vasili Nikolaevich Malozemov. Introduction to minimax. Courier Corporation, 1990
- Richard M. Dudley. Uniform central limit theorems.volume 142. Cambridge university press, 2014.
- Chi Jinand et al. “Is Q-learning provably efficient?” in: arXiv preprint, (2018)
- Yuxi Li. “Deep reinforcement learning: An overview”.in: arXiv preprint, (2017)
- S. SantosoandI. Supriana. “Minimax guided reinforcement learning for turn-based strategygames”. in: 2014 2nd International Conference on Information and Communication Technol-ogy (ICoICT). 2014, pages 217–220.
- David Silverand et al. “A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play”.in: Science 362,6419 (2018), pages 1140–1144.
- David Silverand et al. “Mastering the game of go without human knowledge”.in: nature 550,7676 (2017), pages 354–359
- Felipe Petroski Suchandothers. “Deep neuroevolution: Genetic algorithms are a competitivealternative for training deep neural networks for reinforcement learning”. in: arXiv preprint, (2017)
- Thomas Walsh, Sergiu Goschinand, Michael Littman. “Integrating sample-based planningand model-based reinforcement learning”. in: Proceedings of the AAAI Conference on Artificial Intelligence 24,1 (2010)
- Kaiqing Zhang, Zhuoran Yangand, Tamer Basar. “Multi-agent reinforcement learning: Aselective overview of theories and algorithms”. in: arXiv preprint (2019)