[Technical Post] Novel Method For Using Unsupervised Deep Learning for PDE-based Problems
Recently, a beginning of a series about the connection between deep learning (DL) and partial differential equations (PDE) is emerging with two papers by Dr. Leah Bar and Prof. Nir Sochen entitled "Unsupervised Deep Learning Algorithm for PDE-based Forward and Inverse Problem" and "Strong Solutions for PDE-Based Tomography by Unsupervised Learning ".
In these papers, the authors use unsupervised deep learning in order to find the solution for a given 2-dimensional spatial and time-dimension PDE problem. The solution of this process is mathematically defined by a mapping function from the spatial space (e.g. (x1,y1) points) to their corresponding location (x2,y2) given some point in time (t). From a technical perspective, avoiding as much mathematics as possible, we would focus on the main ideas proposed in this work.
Arcitecture
The arcitecture of the nural network is quite simple relative to the state-of-the-art arcitectures in computer vision, NLP, etc. It consists of a few fully connected layers with tanh activation and linear sum in the last layer. A schematical view of the arcitecture are shown below.
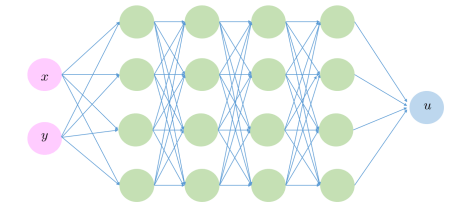
Training
In order to train the DL model to satisfy the PDE with the boundary conditions, the authors defined a new cost function to minimize. The cost function uses two types of distances to handle the complexity of well fit the inner space of the domain and the boundary of the domain. In the first term, the authors used L2 (euclidean distance) with the L_{inf}. The second term is important since the L2 term only forces the equation up to a set of zero measures, while the L_{inf} term takes care of possible outliers. In addition to these, another term is used to minimize the error associated with the boundary condition and as a result, imposes boundary conditions in the model.
This cost function holds a few promises. First, the solutions are smooth analytic functions that are extremely useable in later analysis. Second, the training procedure is mesh-free which means it is easy to adapt for multiple numerical methods such as finite distances, finite elements, finite volume, and others.
This method considered unsupervised learning as the results are untagged, nevertheless is obtained by first calculating the PDE's results either numerically or analytically.
Summary
In the papers, the authors show usage of this method in both forward and inverse problem settings, presenting its robustness and obtain promising results.
A very old idea in mathematics is the approximation of complex functions using simple functions. One can mention famous names as Taylor and Fourier. Another example comes from linear algebra with the idea of eigenvalues and the list is going on. The authors take advantage of this idea as deep networks by their nature use compositions of simple functions such as matrix multiplication and non-linear activations like sigmoid or tanh. This structure enables the approximation of an arbitrary function. Specifically, deep networks can use a relatively large number of degrees of freedom which in turn enables the expressibility of complex functions (such as PDEs).
On a personal note, I hope to see more paper combining state-of-the-art methods from computer science and mathematics combined to provide new ways to solve classical questions in both areas and as so operating as a bridge in these similar but yet so different areas. Both papers presented in this post require a deep understanding of both DL and PDEs and may be hard for audience not familiar with these subjects. Nevertheless, further reading is very recommended.
* All images in this blog post have been taken from the papers themself